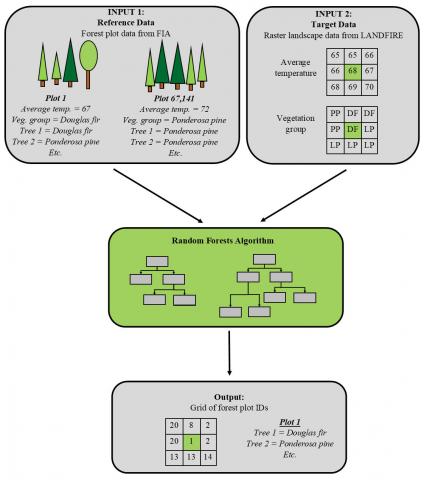
Machine learning matched forest plot data with biophysical characteristics of the landscape to produce a seamless tree-level forest map.
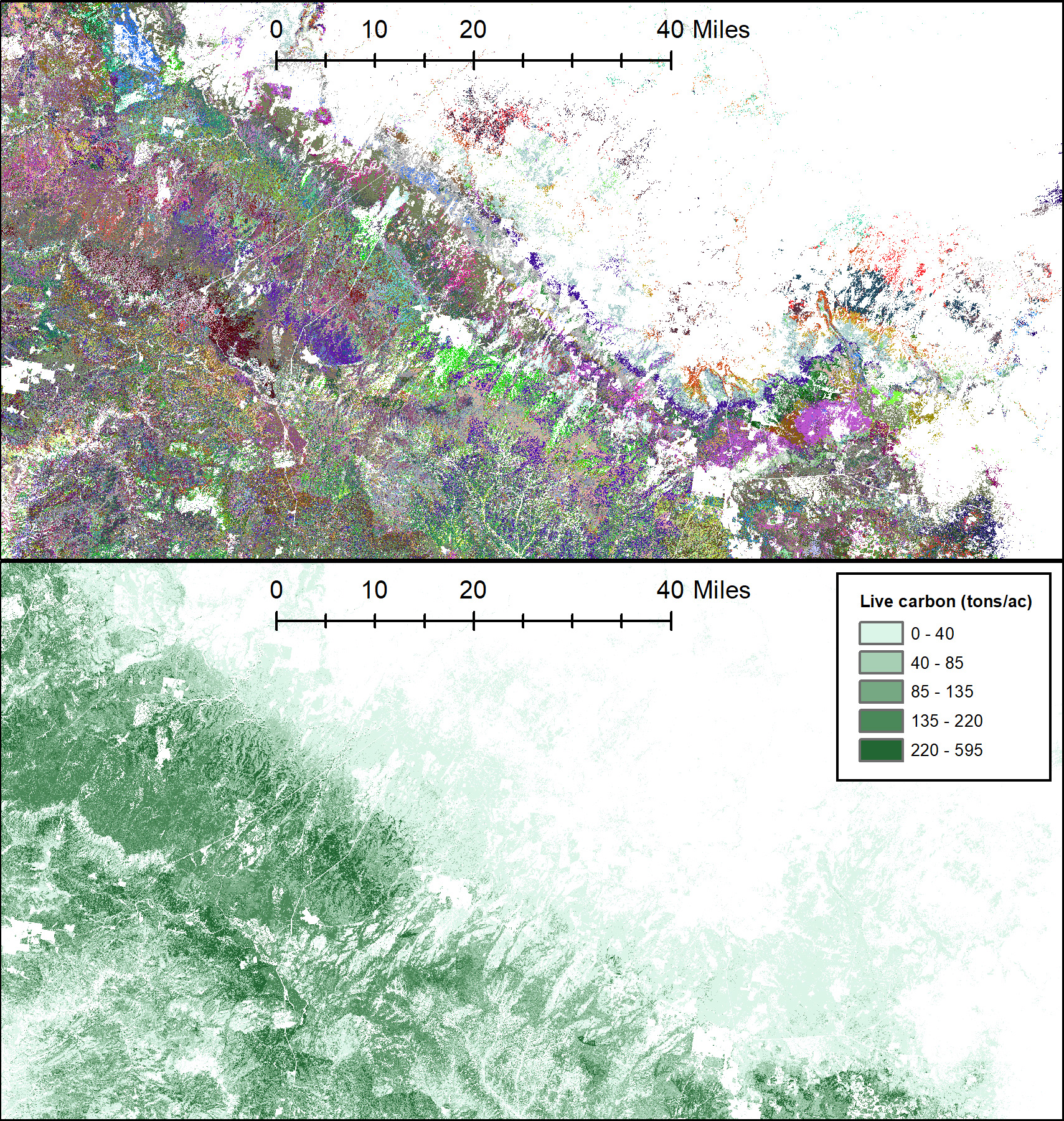
The TreeMap 2016 dataset is a spatial model of the trees in continental US forests. It provides detailed spatial information on forest characteristics including a list of trees for each pixel (with tree species, DBH, height, and live or dead status), and summary information for each pixel including forest type, number of live and dead trees, biomass, and carbon. TreeMap covers the entire forested extent of the continental United States at 30 x 30m resolution, enabling analyses at fine scales. Inputs to TreeMap include detailed forest plot data measured by Forest Inventory Analysis (FIA, https://www.fia.fs.usda.gov/) and national gridded maps of forest cover, height, and vegetation type provided by the LANDFIRE project (https://www.landfire.gov/). TreeMap 2016 includes disturbance as a response variable, resulting in increased accuracy in mapping disturbed areas.
Using random forests (a type of machine learning algorithm) we match the forest plot data to the gridded vegetation maps, producing a seamless model of the trees of the forests of the US. Specifically, the result is a map of plot ID numbers, which identify the best-matching forest plot for each 30x30 pixel in the map. The map of plot ID numbers can be linked back to the FIA databases (https://apps.fs.usda.gov/fia/datamart/datamart.html) to generate maps of any number of forest characteristics, ranging from basal area to biomass to species types.
Some current uses of the dataset include estimation of:
- Forest carbon
- Wildfire risk to forest carbon
- Volume of harvestable wood generated by fuel treatments
- Hydrologic effects of fuel treatments
Read more about the background and development of TreeMap in this Science You Can Use in 5: Seeing the forest AND the trees: TreeMap provides a tree-level forest model.
Learn more about new ways to access and use the TreeMap dataset in this fact sheet:
https://www.fs.usda.gov/research/rmrs/understory/treemap-glance
View the interactive, web-based platform to explore TreeMap products without having to download the full dataset at https://apps.fs.usda.gov/lcms-viewer/treemap.html
Access the TreeMap dataset here: https://www.fs.usda.gov/rds/archive/Catalog/RDS-2021-0074
Snag Hazard Map
Derived from TreeMap 2016, Snag Hazard is a map that classifies forested areas into categories of low, moderate, high, or extreme snag hazard based on snag density (number of dead trees/acre) and height. The Snag Hazard map can help wildland fire managers identify hazardous snag conditions and avoid exposing fire responders in these areas. This Science You Can Use in 5 "Heads Up in a Dead Forest: Using the Snag Hazard Map to Support Safety and Strategic Planning for Fire Responders" describes how the Snag Hazard map can be used to support safety and strategic planning for first responders.
Click on photos for larger view.